
B. Wang*, T. M. Nguyen*, A. L. Bertozzi***, R. G. Baraniuk**, S. J. Osher**. "Scheduled Restart Momentum for Accelerated Stochastic Gradient Descent", arXiv, 2020.
Gihub code: https://github.com/minhtannguyen/SRSGD.
Blog: http://almostconvergent.blogs.rice.edu/2020/02/21/srsgd.
Slides: SRSGD
Stochastic gradient descent (SGD) with constant momentum and its variants such as Adam are the optimization algorithms of choice for training deep neural networks (DNNs). Since DNN training is incredibly computationally expensive, there is great interest in speeding up convergence. Nesterov accelerated gradient (NAG) improves the convergence rate of gradient descent (GD) for convex optimization using a specially designed momentum; however, it accumulates error when an inexact gradient is used (such as in SGD), slowing convergence at best and diverging at worst. In this paper, we propose Scheduled Restart SGD (SRSGD), a new NAG-style scheme for training DNNs. SRSGD replaces the constant momentum in SGD by the increasing momentum in NAG but stabilizes the iterations by resetting the momentum to zero according to a schedule. Using a variety of models and benchmarks for image classification, we demonstrate that, in training DNNs, SRSGD significantly improves convergence and generalization; for instance in training ResNet200 for ImageNet classification, SRSGD achieves an error rate of 20.93% vs. the benchmark of 22.13%. These improvements become more significant as the network grows deeper. Furthermore, on both CIFAR and ImageNet, SRSGD reaches similar or even better error rates with fewer training epochs compared to the SGD baseline.

Figure 1: Error vs. depth of ResNet models trained with SRSGD and the baseline SGD with constant momemtum. Advantage of SRSGD continues to grow with depth.
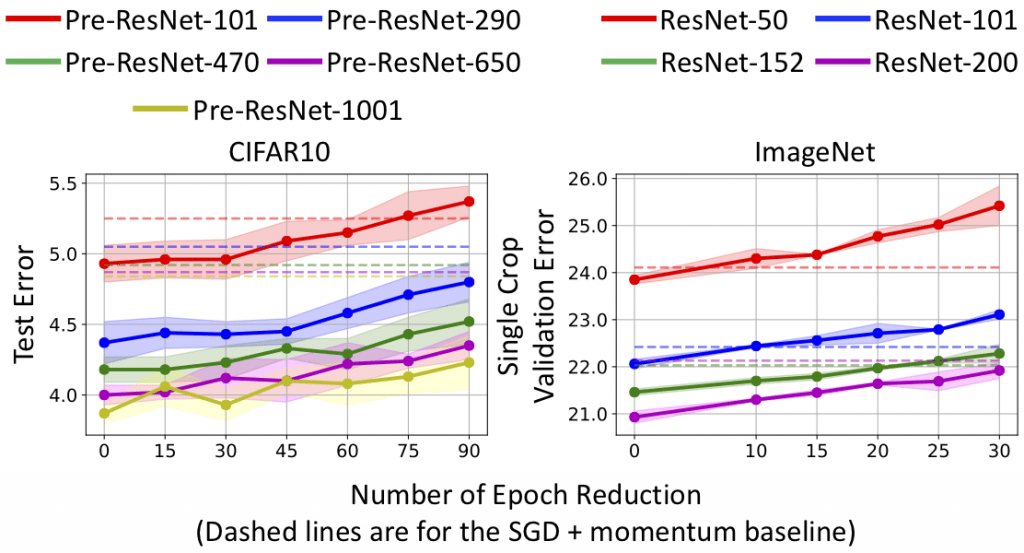
Figure 2: Test error vs. number of epoch reduction in CIFAR10 and ImageNet training. The dashed lines are test errors of the SGD baseline.
* : Co-first authors; **: Co-last authors; ***: Middle author
 Mark Davenport (PhD, 2010) as been selected as a Rice Outstanding Young Engineering Alumnus. The award, established in 1996, recognizes achievements of Rice Engineering Alumni under 40 years old. Recipients are chosen by the George R. Brown School of Engineering and the Rice Engineering Alumni (REA).
Mark Davenport (PhD, 2010) as been selected as a Rice Outstanding Young Engineering Alumnus. The award, established in 1996, recognizes achievements of Rice Engineering Alumni under 40 years old. Recipients are chosen by the George R. Brown School of Engineering and the Rice Engineering Alumni (REA).








